CMU15-445 Lab3 : 执行器实现
Task1 - System Catalog
维护一个内部的目录来跟踪数据库内的元数据。
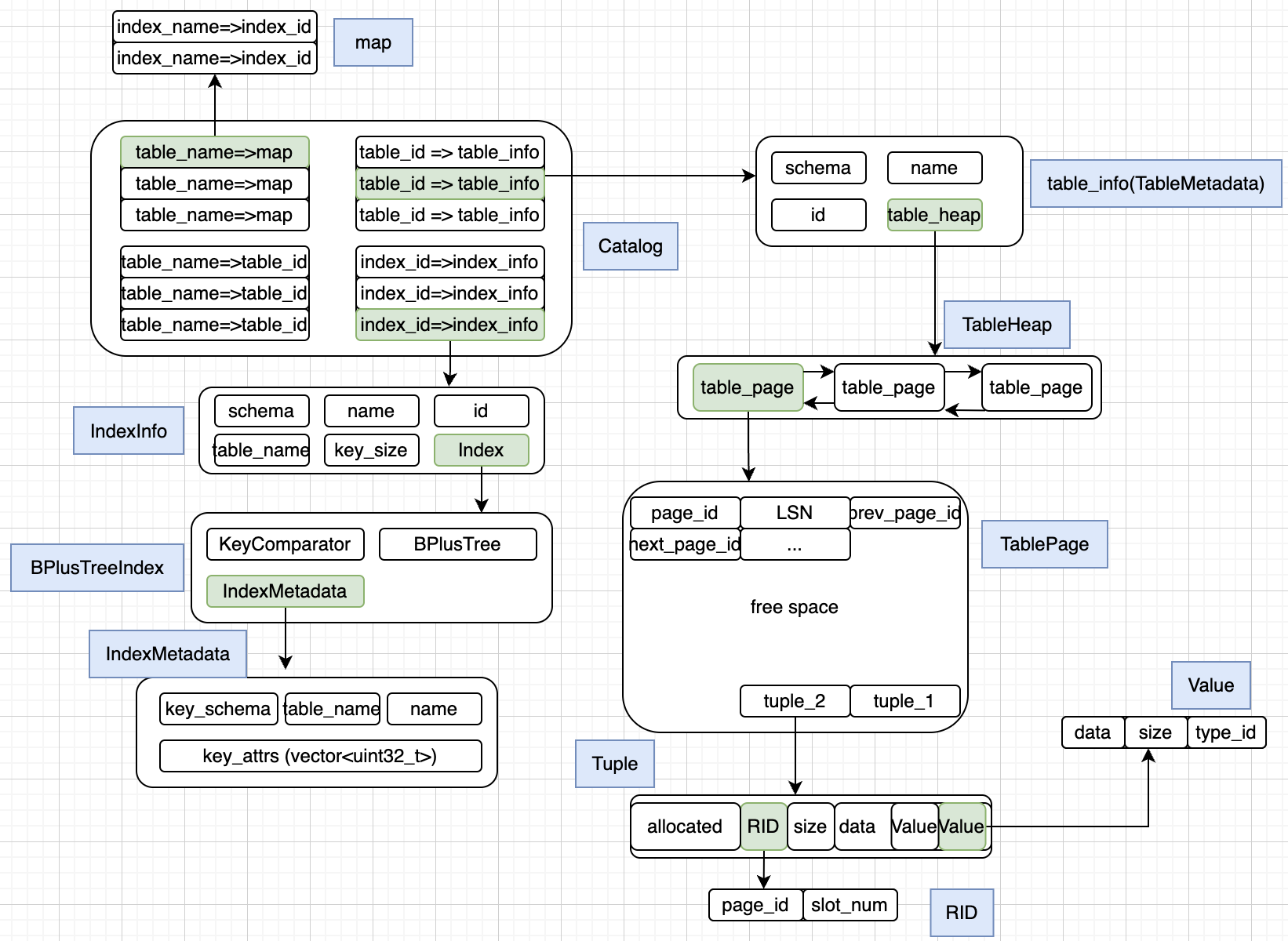
Schema (class)
表的结构信息,不包含表的实际数据。
1 | |
这些信息就由 Schema 来储存,真实数据数据会通过 Tuple 来储存。
TableHeap 与 Schema 结合才是完整的表。
Column (class)
表示列的信息。
1 | |
TableHeap (class)
表示磁盘上的物理表。
由多个 TablePage 组成,插入时从第一张 TablePage 开始,不能插入就尝试下一张,或者新建一张(没有下一张时),只到由空余的位置插入 Tuple。
更新,删除,查找通过 Rid::GetPageId() 可以轻松在 BufferPoolManger 中找到对应的 TablePage,并且通过 Rid::GetSlotNum() 在 TablePage 中找到对应的 Tuple。
TablePage (class)
继承 Page
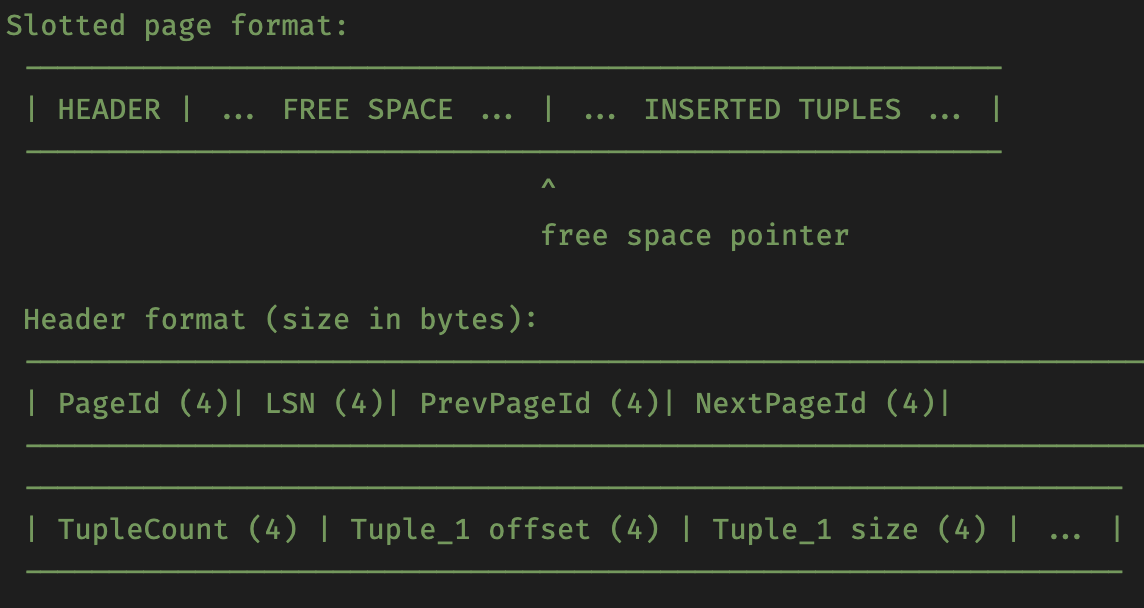
Header 的大小是 24 ,使用偏移量来获得 Page 中的每个值。
插入 Tuple
使用 memcpy 将 Tuple::Data 拷贝一份到TablePage::Data 对应的位置上。
同时会修改参数 Rid 做为这条 Tuple 的标志符,接下来更新、删除、查找这条 Tuple 都要依靠 Rid。
更新 Tuple
使用memmove 来将原来的 TablePage::Data 中要被更新的 Tuple::Data 移动到TablePage::Data后面。
重新设置TablePage::Data 中的 Tuple::Data的偏移量。
删除 Tuple
MarkDelete
只是标记为被删除,实际 TupleCount 和 free_space_pointer 都没有被改变,之后可以通过 TablePage::RollbackDelete(const RID &rid,...) 来恢复。
ApplyDelete
使用 memmove 将内容移除,不可恢复,删除后同样需要设置 TablePage::Data 中的 Tuple::Data的偏移量。
Tuple (class)
1 | |

Rid (class)
通过 Rid 就能快速找到 TablePage 中的 Tuple 。
1 | |
TableIterator (class)
为 sequential scan TableHeap 提供的迭代器。
*TableIterator 会返回一个 Tuple
TableIterator 只会向前迭代,每次都是迭代一张表(而不是一张 Page,一张表可能有多个 Page 组成 )。
TableMetadata (class)
1 | |
将 TableHeap 与 Schema 封装起来组成完整的表,同时加入表名称 name 和表的标示号 oid_ 来帮助 Catalog 管理多个表。
IndexInfo (class)
1 | |
观察上面的 TableMetadata 会发现少了索引,IndexInfo 就表示了这个索引,而 Catalog 的作用就是实现 TableMetadata 与 IndexInfo 关联起来,真正实现完整的表。
Catalog (class)
1 | |
通过给定的类成员就能够推断出 Catalog 是如何关联 TableMetadata 和 IndexInfo 以及使用表名称/索引表名称关联 TableMetadata/IndexInfo。
CreateTable
TableMetadata *CreateTable(Transaction *txn, const std::string &table_name, const Schema &schema)
创建一个新表(初始化一个 TableMetadata),创建完新表就要在哈希表中关联起来 table_oid_t => TableMetadata, table_name => table_oid_t
GetTable
TableMetadata *GetTable(const std::string &table_name)
TableMetadata *GetTable(table_oid_t table_oid)
通过创造表时做的哈希映射实现即可,要注意的是如何从 std::unique<TableMetadata> 获得裸指针。
CreateIndex
1 | |
这里的 Index 是指的 BPlusTreeIndex(基类指针可以指向派生类)。
1 | |
可以看到 BPlusTreeIndex 是包含了一个 BPlusTree 。
GetIndex
IndexInfo *GetIndex(const std::string &index_name, const std::string &table_name)
IndexInfo *GetIndex(index_oid_t index_oid)
与 TableMetaData 的取法相同。
Task2 - Executors
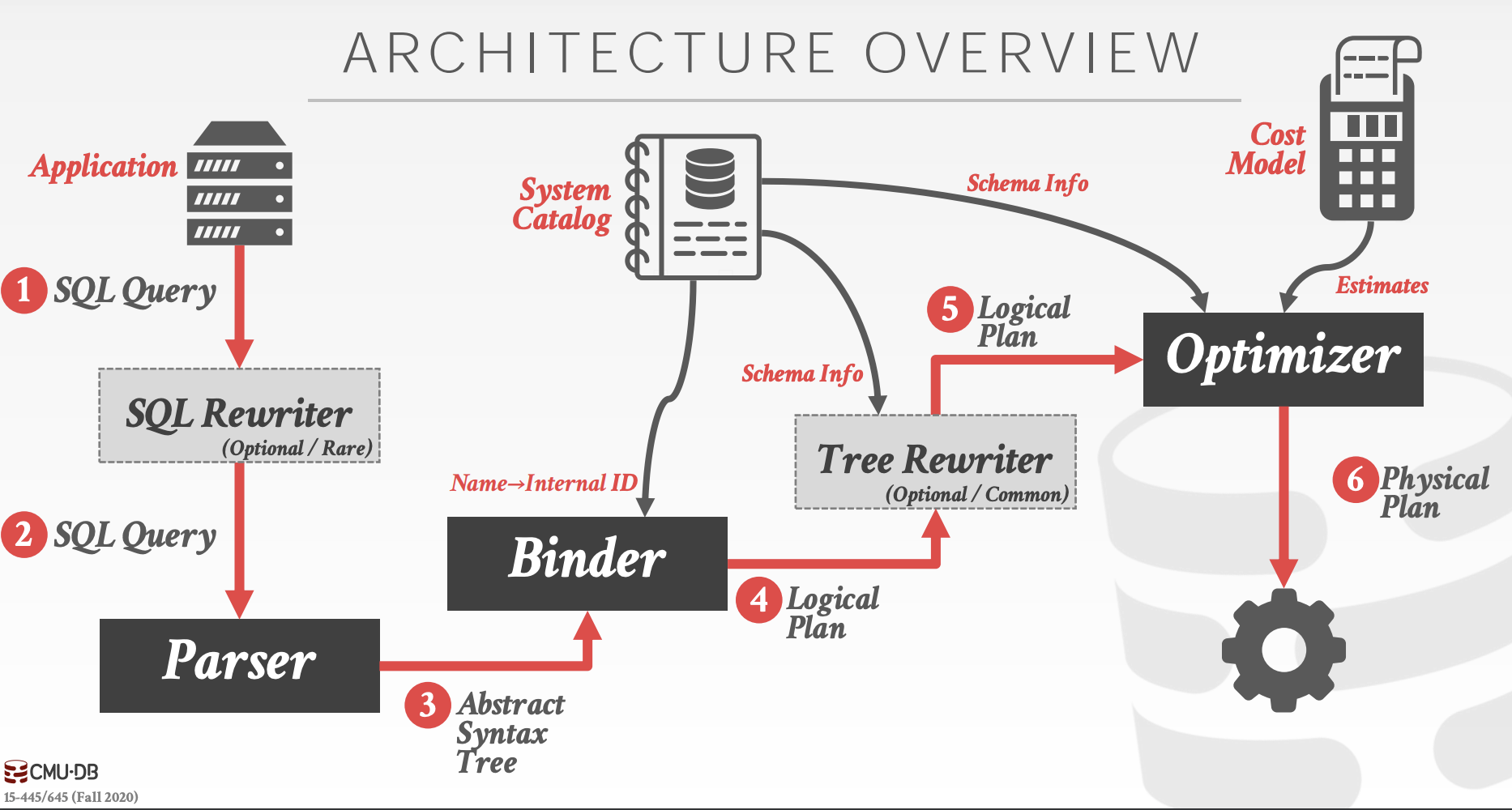
Parser
SQL 语句通过 Parser 生成抽象语法树 AST (编译原理中的 AST)。
Binder
1 | |
需要被绑定的是 id 与 table1 ,这两个会被绑定到对应的实体上(各种 C++ 中的类),这用 Bustub 就能理解这些标记了。
Planner
Binder 结束后,Planner 根据 Binder 生成的树生成一颗初步的查询计划树。
1 | |
生产的查询计划树为 :
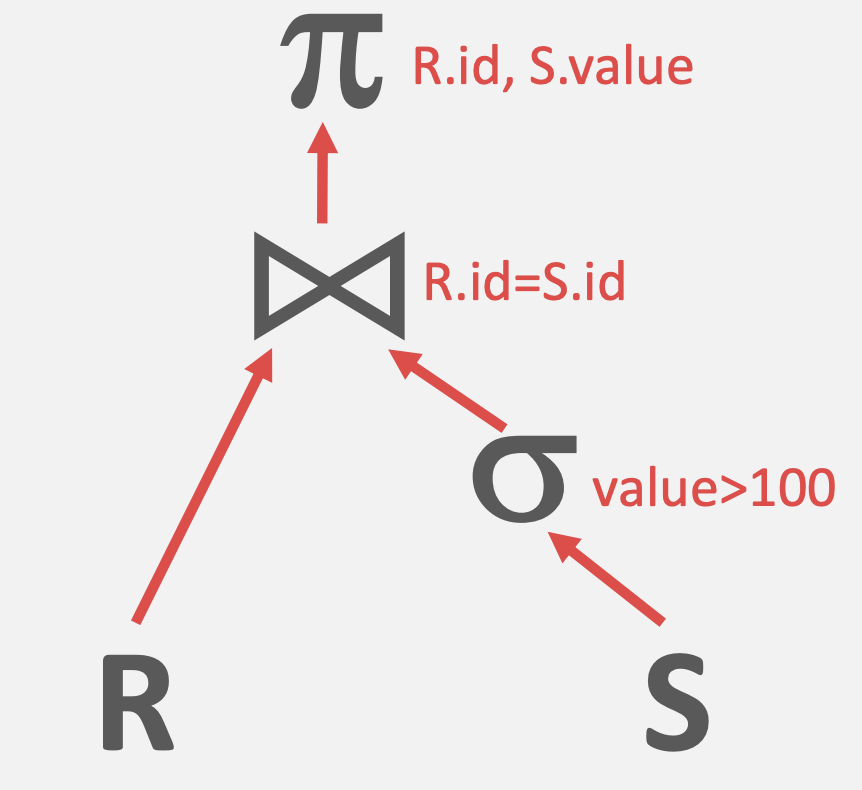
叶子节点的结果会返回给他的父节点,最后由根结点得到最终结果。
Optimizer
对 Planner 生成的查询计划进行修改优化,生成最终的查询计划。
Rule-based ,根据已有的规则进行修改优化,不需要知道实际的数据。
Cost-based ,先读取数据并通过统计学模型来计算不同形式但等价的查询计划的 cost,选取 cost 最小的作为最终的查询计划。
Bustub 采用了第一种。
关于 Rule-based 的一些例子:
Predicate Pushdown
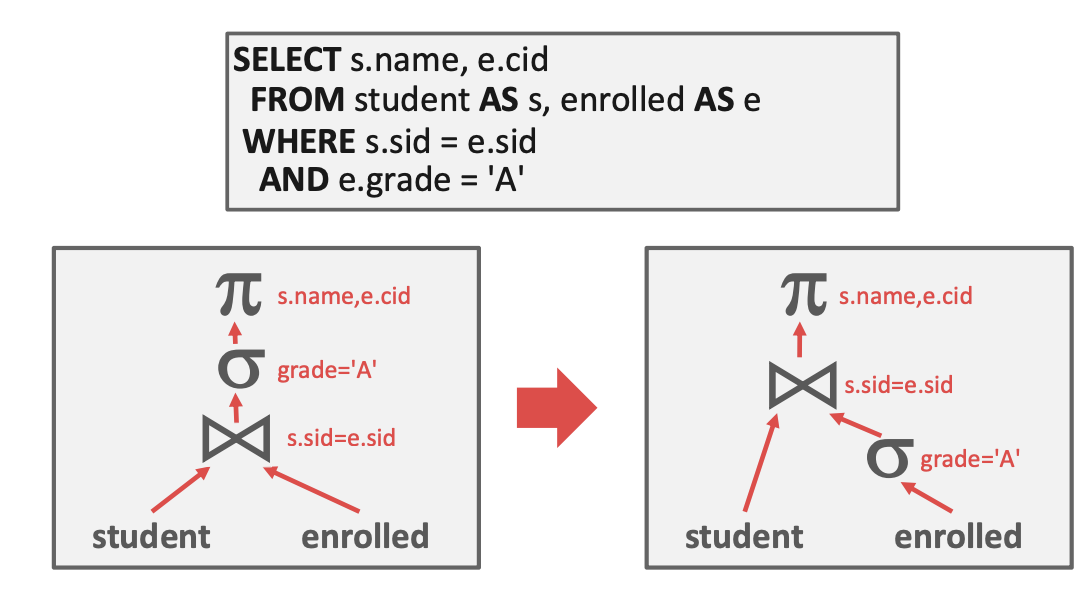
尽可能早的进行过滤操作,这样想上层节点返回的行会更少。
Projection Pushdown
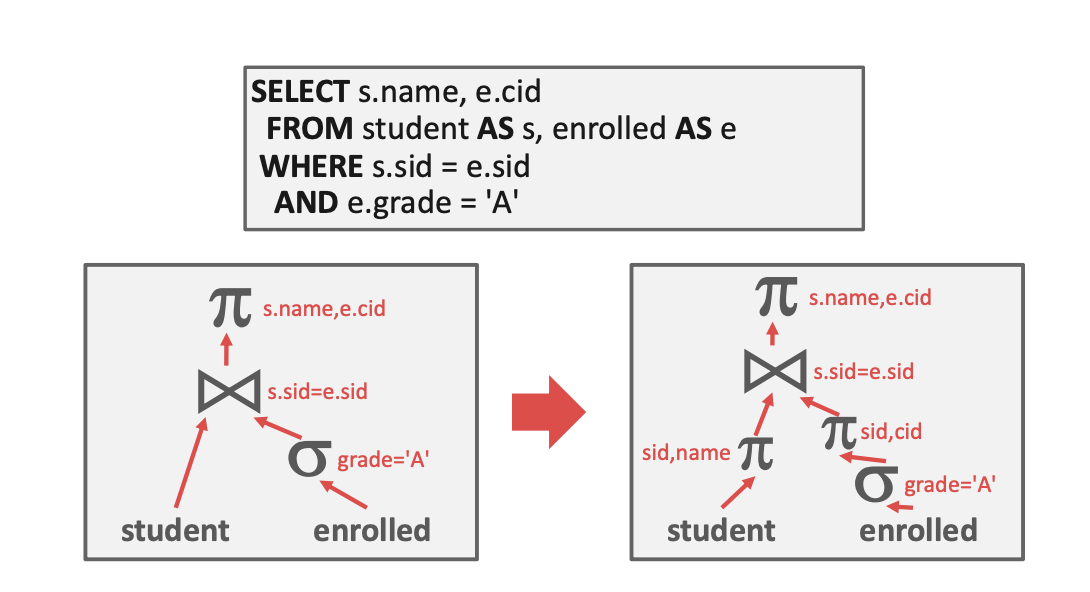
向上层节点返回尽可能少的列,减少无效数据的开销。
Unnecessary Predicate
1 | |
删除不必要的谓词,
1 | |
Join Elimination
1 | |
删除不必要的连表,
1 | |
Ignoring Projection
1 | |
删除不必要的投影,
1 | |
Merging Predicate
1 | |
合并谓词,
1 | |
Executor
在生成最终的查询计划后,就可以生成真正的可执行的算子了,要实现的就是这部分的内容。
算子的执行模型分为三类:Iterator、Materialization、Vectorization Model。
Bustub 使用 Iterator Model。
火山模型/迭代器模型 (Iterator/Volcano/Pipeline Model)
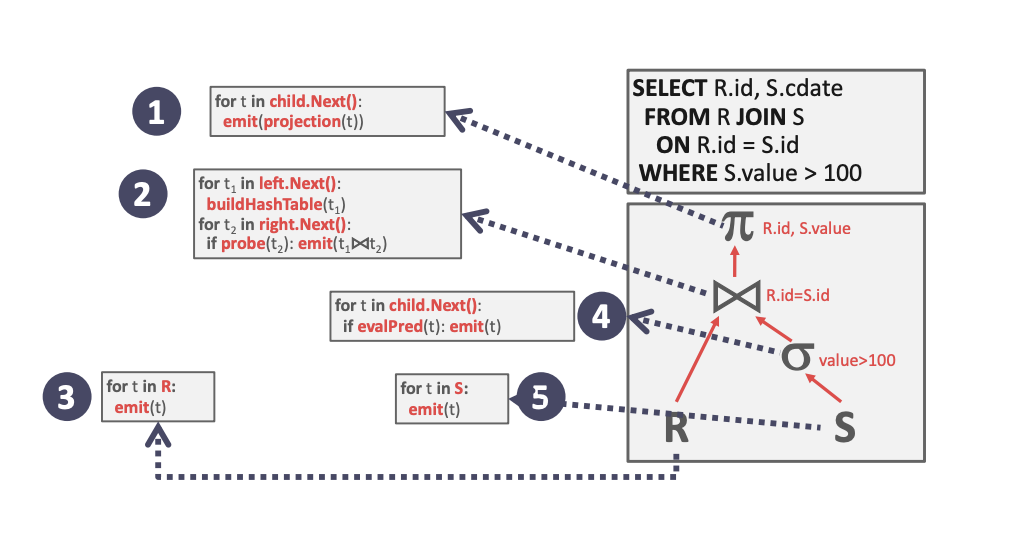
每次执行 Next() 都会返回一个元组或空标记。父节点的 Next() 通过调用子节点的 Next() 来获取子节点的结果。
1 | |
从跟节点开始执行循环,每次都从叶子节点开始一层一层向上返回数据,直到跟节点,然后进行下一次循环。
这样做一次只调用一行数据,内存占用较小,但是函数的开销就会大一些,Bustub 中的 Next() 是虚函数。
物化模型 (Materialization Model)
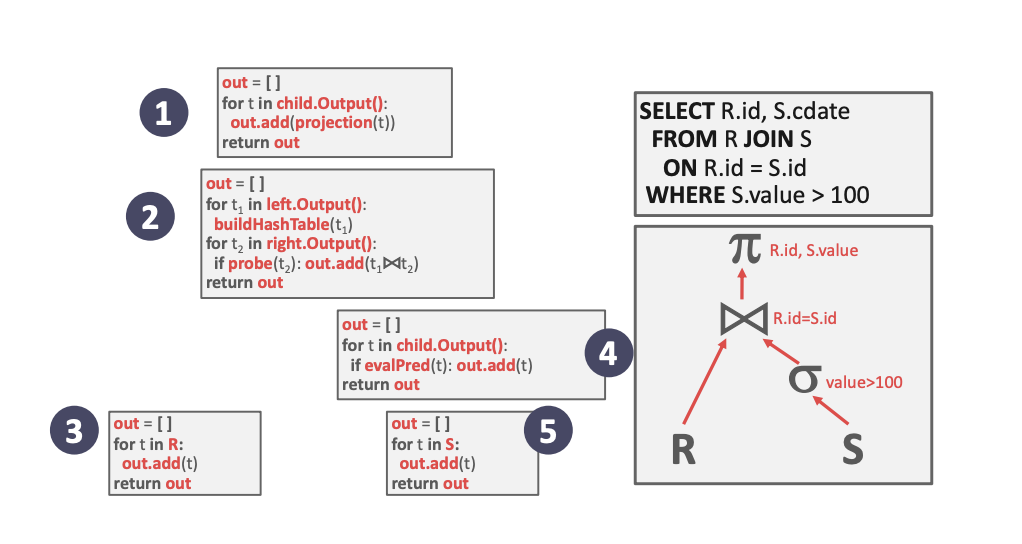
每次执行 Next() 会返回全部数据,算子会将要处理的数据全部处理后一起返回。
1 | |
这种模型消耗的内存会更大,适合处理要返回的数据很少的情景。
向量模型 (Vectorization Model)
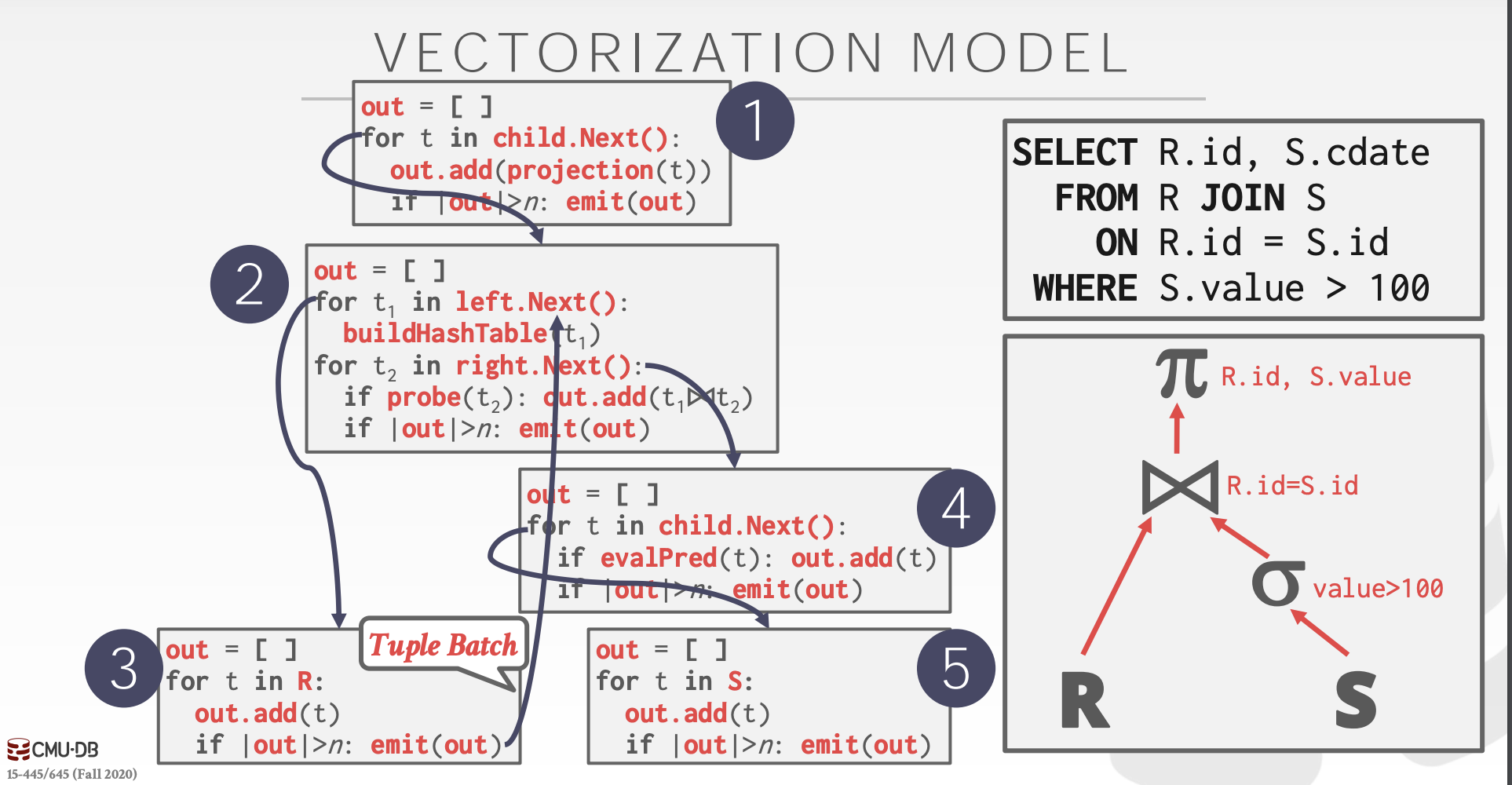
是上面两种模型的中和,调用一次 Next() 返回一批数据,可以使用 SIMD 进行优化。